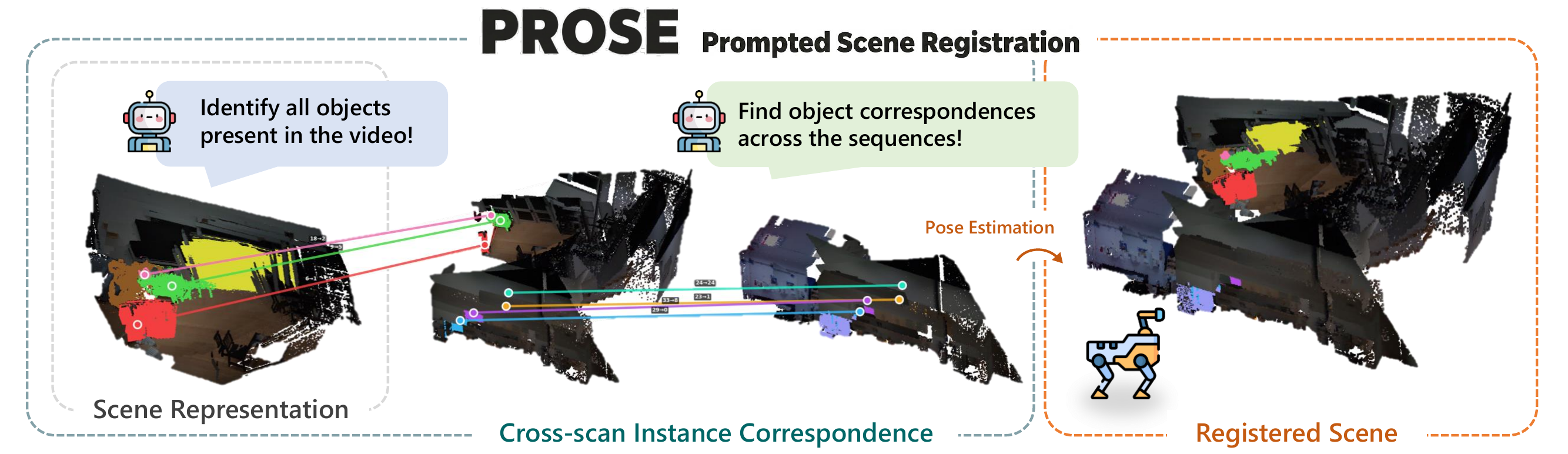
Given two egocentric RGB sequences of the same indoor space captured at different times, PROSE recovers the rigid transform aligning them — and produces an open-vocabulary 3D scene graph for each capture along the way.
Given two egocentric RGB sequences of the same indoor space captured at different times, PROSE recovers the rigid transform aligning them — and produces an open-vocabulary 3D scene graph for each capture along the way.
Registering two captures of the same indoor space taken at different times underpins persistent spatial memory for robots and AR systems, yet the realistic version of this task is egocentric and its most scalable form is RGB-only. Head-mounted cameras yield blurry, fast-moving, partially overlapping views from which dense geometry is hard to recover. Classical registration leans on exactly the clean point clouds this setting lacks, while learned scene-graph methods require a pre-built or annotated graph and a trained matcher that we find brittle under egocentric data. We take a different route, using a pretrained vision-language model as the source of both scene understanding and cross-scan matching. Our method, PROSE (Prompted Scene rEgistration), lifts each RGB sequence into an object-level 3D scene graph using off-the-shelf foundation models for geometry, segmentation, and language, then prompts the same VLM to match object instances across the two RGB sequences. To make this matching tractable and reliable, we leverage object heights as a prior and verify each proposed match with a paired same/different query, then solve for the rigid transform by hypothesizing a candidate per matched object and selecting the one with the strongest geometric consensus. PROSE adds no learned parameters and requires no depth sensor, training, or annotated graph. On the egocentric Aria Digital Twin and Aria Everyday Activities benchmarks, it outperforms both geometric and learned scene-graph baselines in registration accuracy, on ground-truth and RGB-reconstructed point clouds alike, and the scene graph it produces transfers directly to downstream tasks.




The actual input: head-mounted egocentric RGB views of the same scene, captured at different times (Aria Digital Twin).
A single pretrained VLM drives both scene understanding and cross-scan matching — no fine-tuning anywhere in the pipeline.
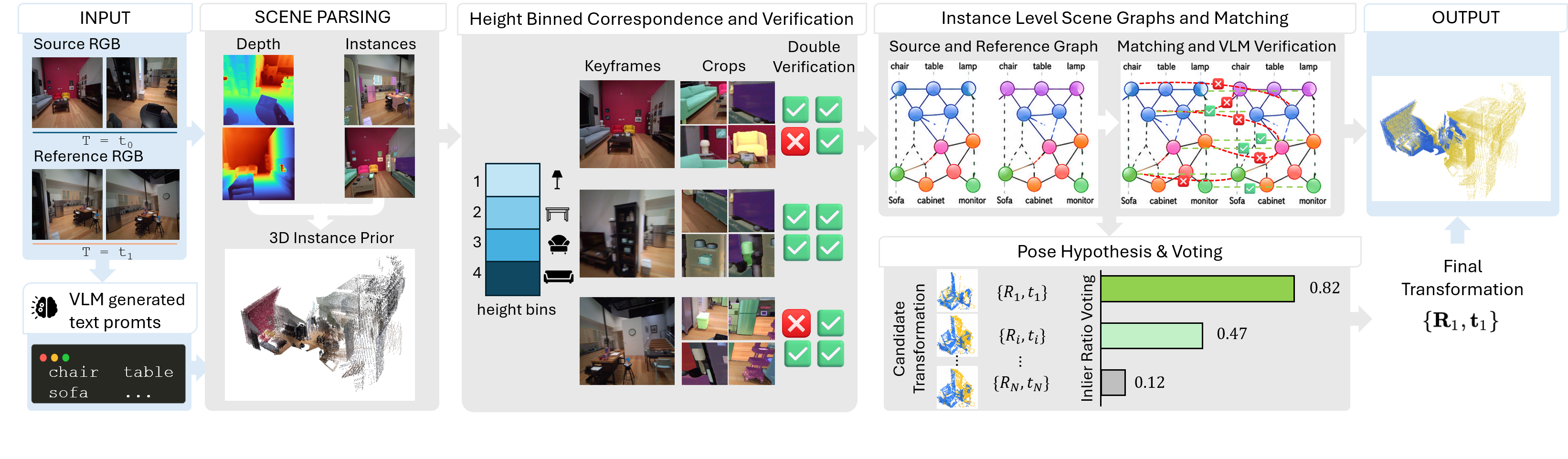
From two egocentric RGB scans of the same scene at different times, PROSE parses each into a per-scan 3D scene graph, matches instances across scans, and estimates the rigid transform by generating one candidate per matched pair and selecting the highest-inlier-ratio hypothesis.
Each RGB sequence is lifted to per-frame depth and poses by a geometric foundation model. A VLM lists the scene's landmark objects, SAM 3 turns the names into temporally consistent instance masks, and a voxel-revote fusion step consolidates everything into an object-level 3D scene graph per scan.
Instances are split into quantile bins along the gravity axis, so a ceiling lamp never competes with a floor rug. Within each bin, the VLM matches crops labeled with shared-namespace Set-of-Marks markers, and every candidate is re-checked with paired same?/different? prompts to expose hallucinated matches.
Each matched pair yields its own rigid-transform hypothesis via per-instance RANSAC on descriptor correspondences. Hypotheses are scored by scene-wide inlier ratio and the strongest geometric consensus wins — so a minority of bad matches cannot corrupt the final transform.
PROSE vs. the strongest scene-level baseline (TEASER++) in each setting. Higher RR ↑ is better; lower RRE ↓ and RTE ↓ are better. The lead widens exactly where it matters: clouds reconstructed from RGB.
Drag to rotate, scroll to zoom — cameras are synced across panels.
Total-split results on ADT and AEA. Bold = best, underline = second best within each cloud setting.
| Method | ADT · GT clouds | ADT · VGGT-Ω clouds | AEA · VGGT-Ω clouds | ||||||
|---|---|---|---|---|---|---|---|---|---|
| RR (%) ↑ | RRE (°) ↓ | RTE (m) ↓ | RR (%) ↑ | RRE (°) ↓ | RTE (m) ↓ | RR (%) ↑ | RRE (°) ↓ | RTE (m) ↓ | |
| TEASER++ FPFH | 80.3 | 8.83 | 0.40 | 44.4 | 17.11 | 0.97 | 42.9 | 18.87 | 2.55 |
| TEASER++ FCGF | 79.4 | 9.63 | 0.44 | Fail to converge | Fail to converge | ||||
| GeoTransformer | Out of Memory | Out of Memory | Out of Memory | ||||||
| BUFFER-X | 61.7 | 10.57 | 0.59 | 37.1 | 16.95 | 1.03 | 34.5 | 20.35 | 2.44 |
| SG-Reg | 46.9 | 19.76 | 2.12 | 19.1 | 29.58 | 3.27 | 19.4 | 27.06 | 3.52 |
| Ours FPFH | 82.5 | 7.44 | 0.30 | 49.9 | 15.71 | 0.70 | 47.9 | 17.91 | 1.84 |
| Ours FCGF | 89.2 | 4.16 | 0.17 | 50.0 | 13.21 | 0.63 | 58.5 | 9.04 | 0.99 |
| Ours GeoTrans | 78.8 | 8.85 | 0.36 | 56.2 | 12.55 | 0.59 | 65.5 | 12.71 | 1.39 |
No single descriptor backend dominates across the three "Ours" rows — the gains come from the VLM correspondence stage, not the descriptor. GeoTransformer OOMs at scene level but works fine as a PROSE backend, since per-instance registration keeps each problem small.
The same open-vocabulary scene graph that drives registration supports object-goal path planning with RRT on a real iPad capture — emulating a quadruped navigating 50 cm above the floor.

Robotic demo. Real-world assessment with a quadruped robot.
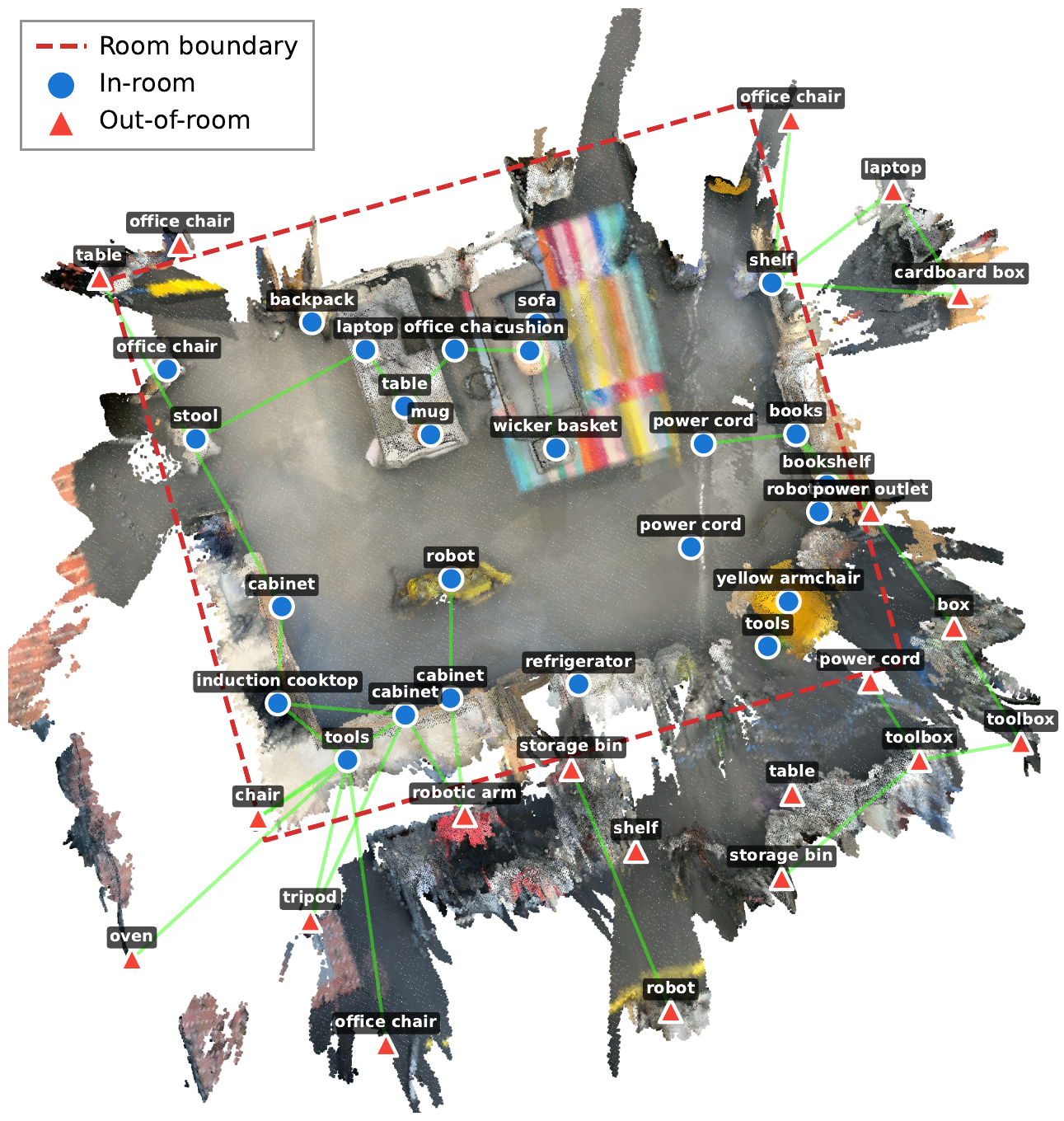
Bird's-eye view of the reconstructed open-plan room with the labeled scene graph (in-room vs. out-of-room instances).
| Method | SRroom ↑ | SRnear ↑ | SRfar ↑ | SRcross ↑ | Ninst | Npairs |
|---|---|---|---|---|---|---|
| FM-Fusion* | 100* | 100* | 100* | – | 5 | 9 |
| ConceptGraphs | 46.2 | 47.1 | 46.8 | 38.1 | 33 | 379 |
| Ours | 49.6 | 62.1 | 47.1 | 40.4 | 192 | 500 |
*FM-Fusion recovers valid graphs for only 2 rooms — its perfect rate reflects negligible coverage, not planning quality.
@article{chen2026prose,
title = {PROSE: Training-Free Egocentric Scene Registration with Vision-Language Models},
author = {Chen, Zhiang and Lee, Nahyuk and Sun, Boyang and Kwon, Taein and Pollefeys, Marc and Bauer, Zuria and Hong, Sunghwan},
journal = {arXiv preprint arXiv:2606.16569},
year = {2026}
}